Malerhände
This is about the differntiation of illustrator in the Wenceslas bible.
Features
Face detection
- deepface
- dlib
- mtcnn
- mediapipe
- opencv
- retinaface
- ssd
- yolov8
- yunet
- insightface (also reimplemnted by deepface retinaface, but taht is worse)
Only insightface does properly report the face landmarks. It's also the best performing so we use that.
This topic is described in paper_humanities_wenzelfacedetection.
Face comparison features
- VGG-Face
- Facenet
- Facenet512
- OpenFace
- DeepFace
- DeepID
- ArcFace
- Dlib
- SFace
- GhostFaceNet
Other comparison features
- ccv
- lbp
- lpips
Data
Face are detcted with insightface (Tiles with 3000 tilesize, scale factor 1, and rotation factor 0° and ±45°) and face landmarks (for alignment are stored). Tags come from the groundtruth if it can be matched with detected faces.
Transform
Derived from that we have two basic extractions, normal (no tag) and transformed (t).
| normal | transformed |
|---|---|
 |
 |
Transforms are certainly helpful for face comparison but should also be helpful to non-face features which are not rotation invariant. The drawback is that the face detection algorithm should provide face landmarks with which to align the faces. Not all of them provide face landmarks so this prevents the use of some face detectors, although the current best from the prior paper, insightface, does provide face landmarks.
Context
This is the additional image information around the face which is included in the extracted image, either with 50 pixel context on each side from the source image (c50) or no additional context (nc), see above for nc examples.
| c50 | c50t |
|---|---|
 |
 |
This is used for face comparison, as face algorithm often have an assumption about face to image ratios which the images without context might exceed. For texture features the extra context is likely detrimental as it will change even if the person does not.
First Evaluation
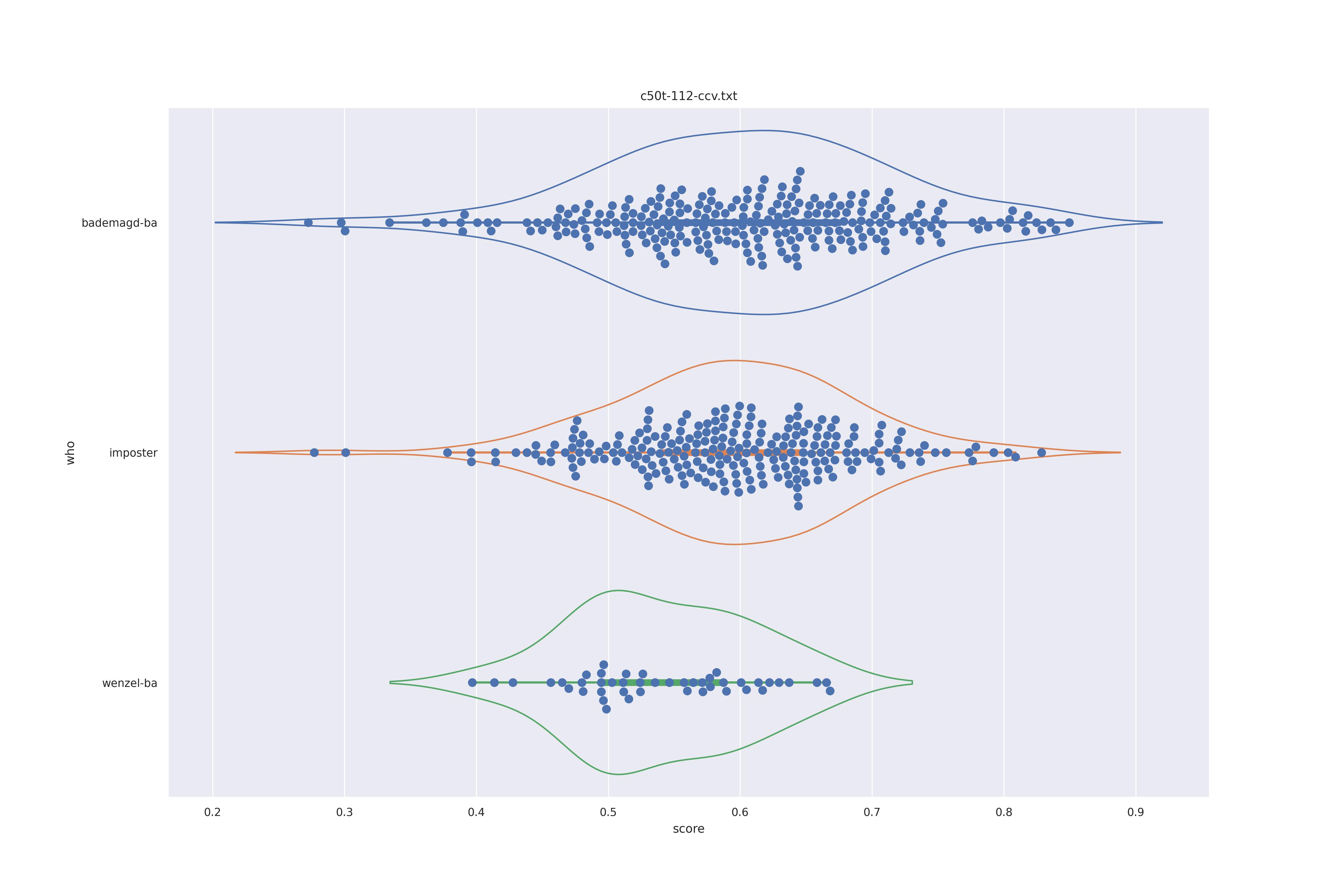
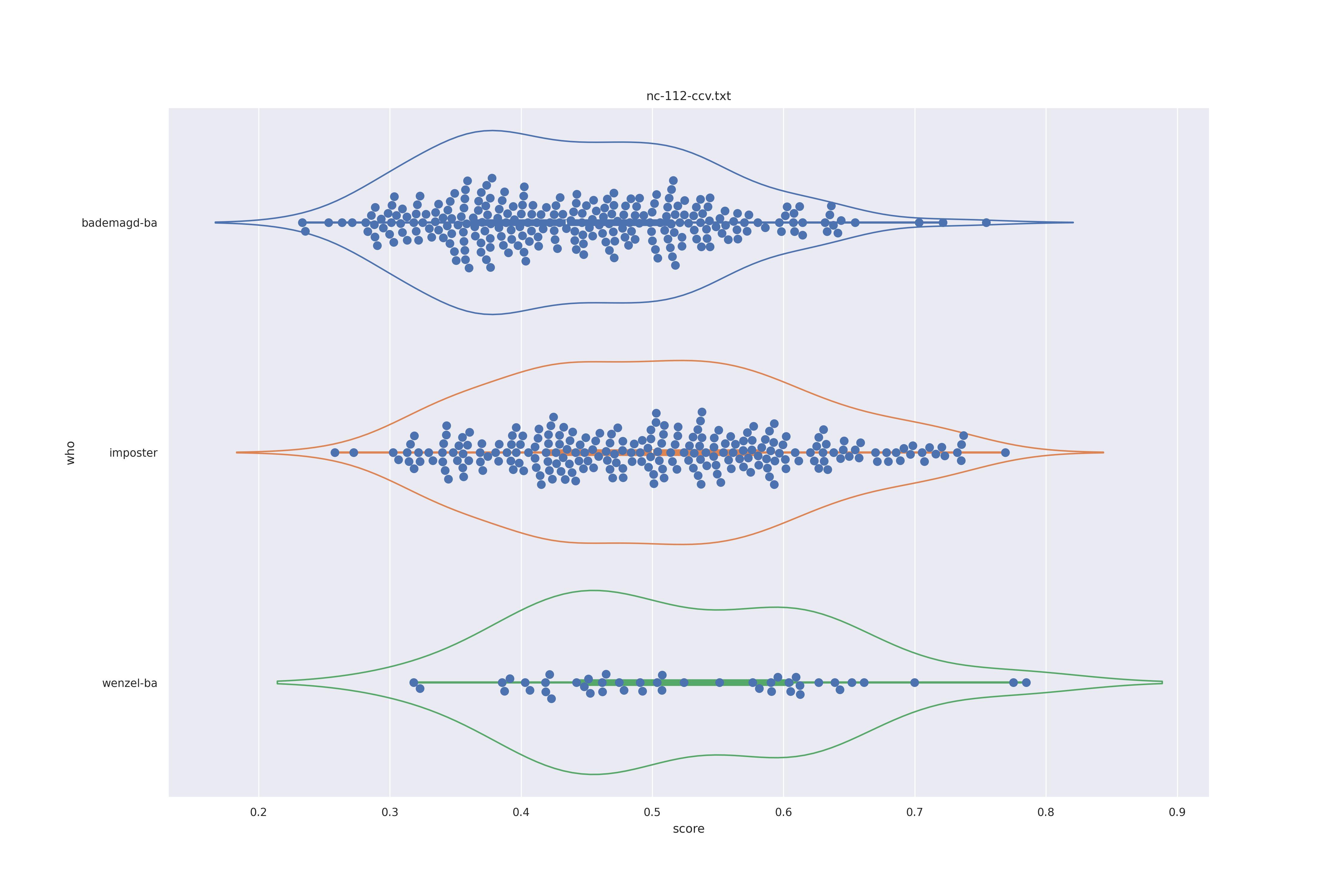
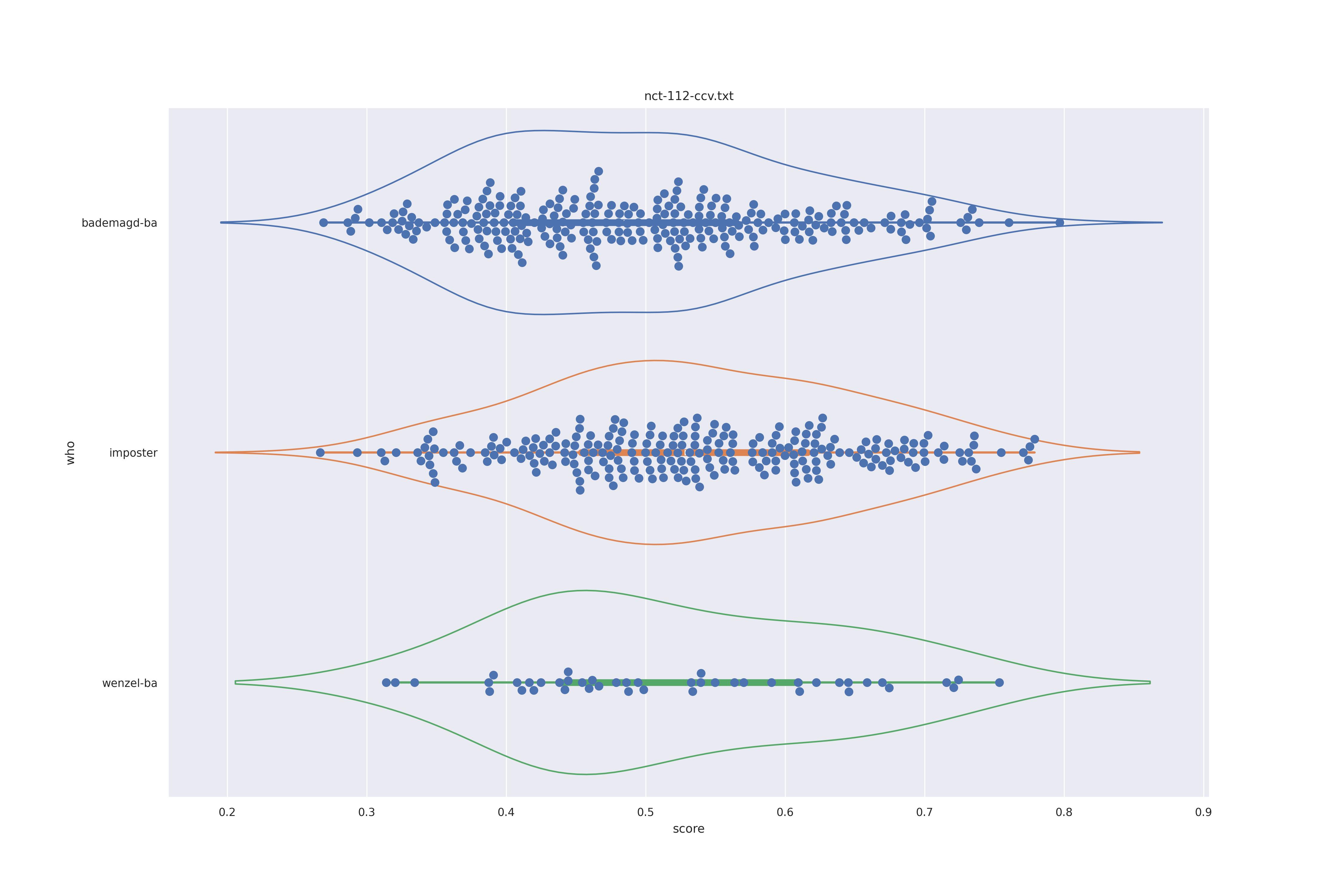
The basic idea is this, if a method can not differentiate between two figures (Wenzel vs. Bademagd) then it is useless in trying to differntiate between potential painters of a single figure (wenzel).
Non-face features
First let's look at the non-face recognition feature comparison. The expectation is that the transform may help, and that context does not help.
The display is bademagd on top (blue), then imposter comparisons (bademagd vs. wenzel in orange) and then wenzel at the b ottom (green).
| Method | c50 | c50t | nc | nct |
|---|---|---|---|---|
| ccv | 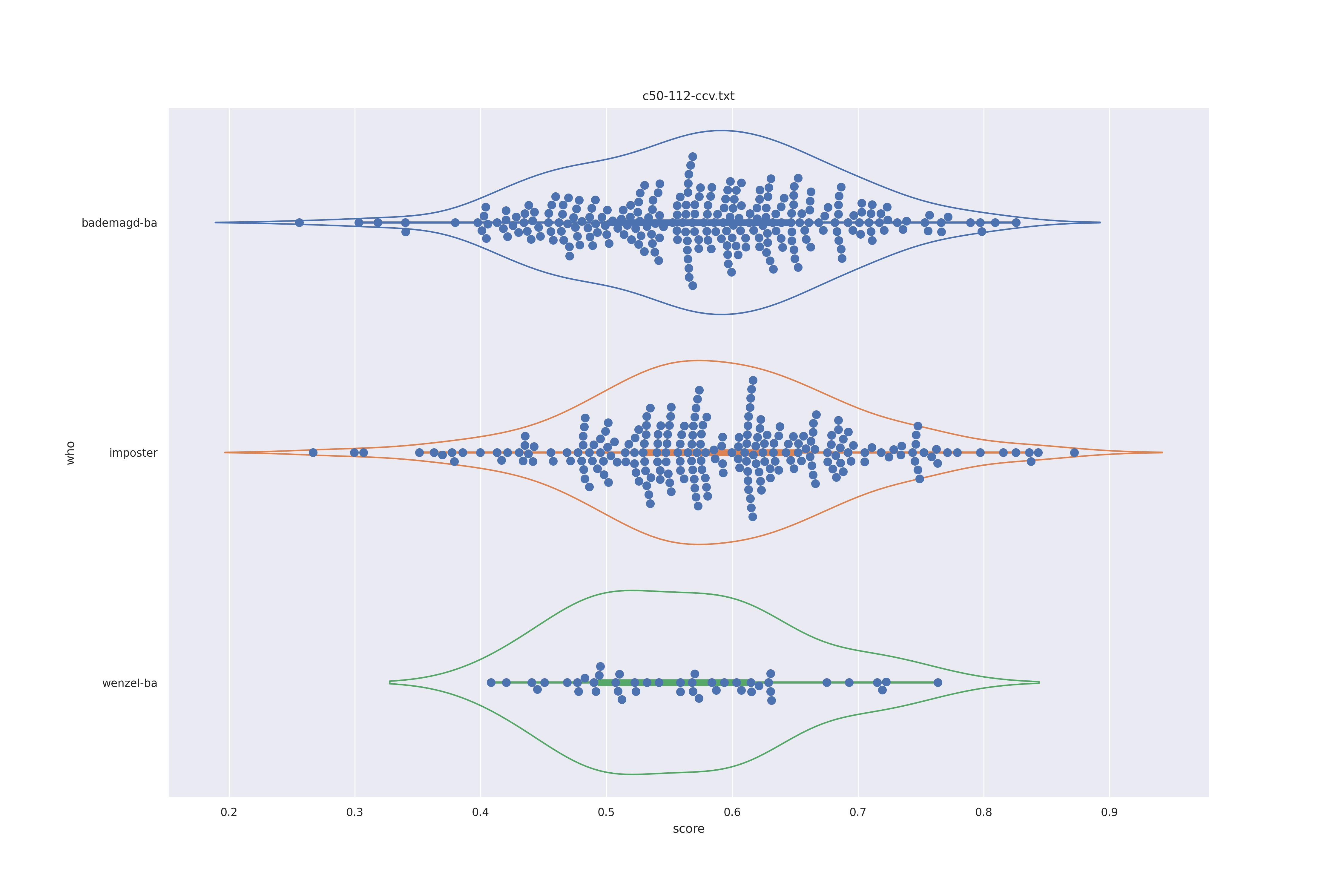 |
 |
 |
 |
| lbp | 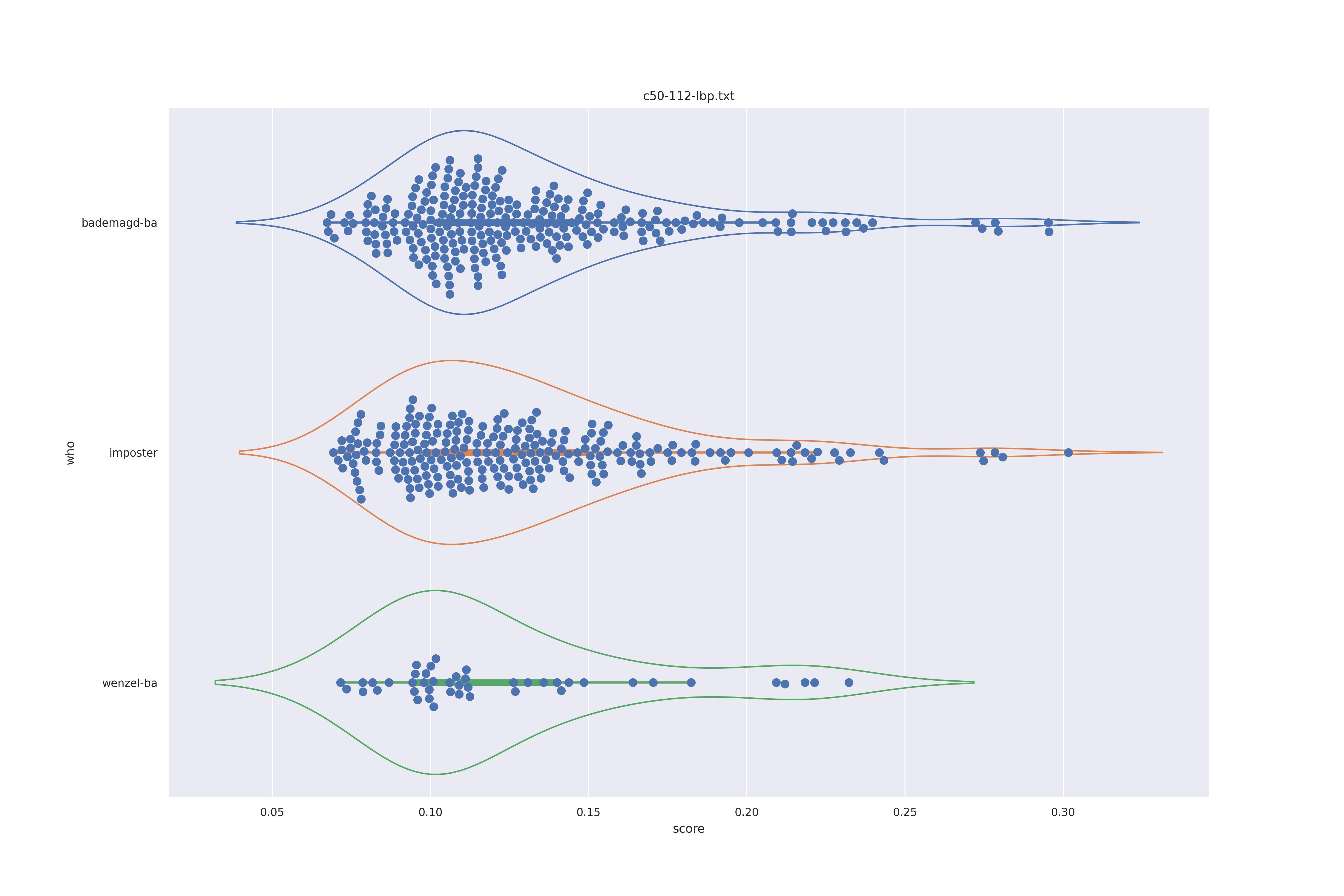 |
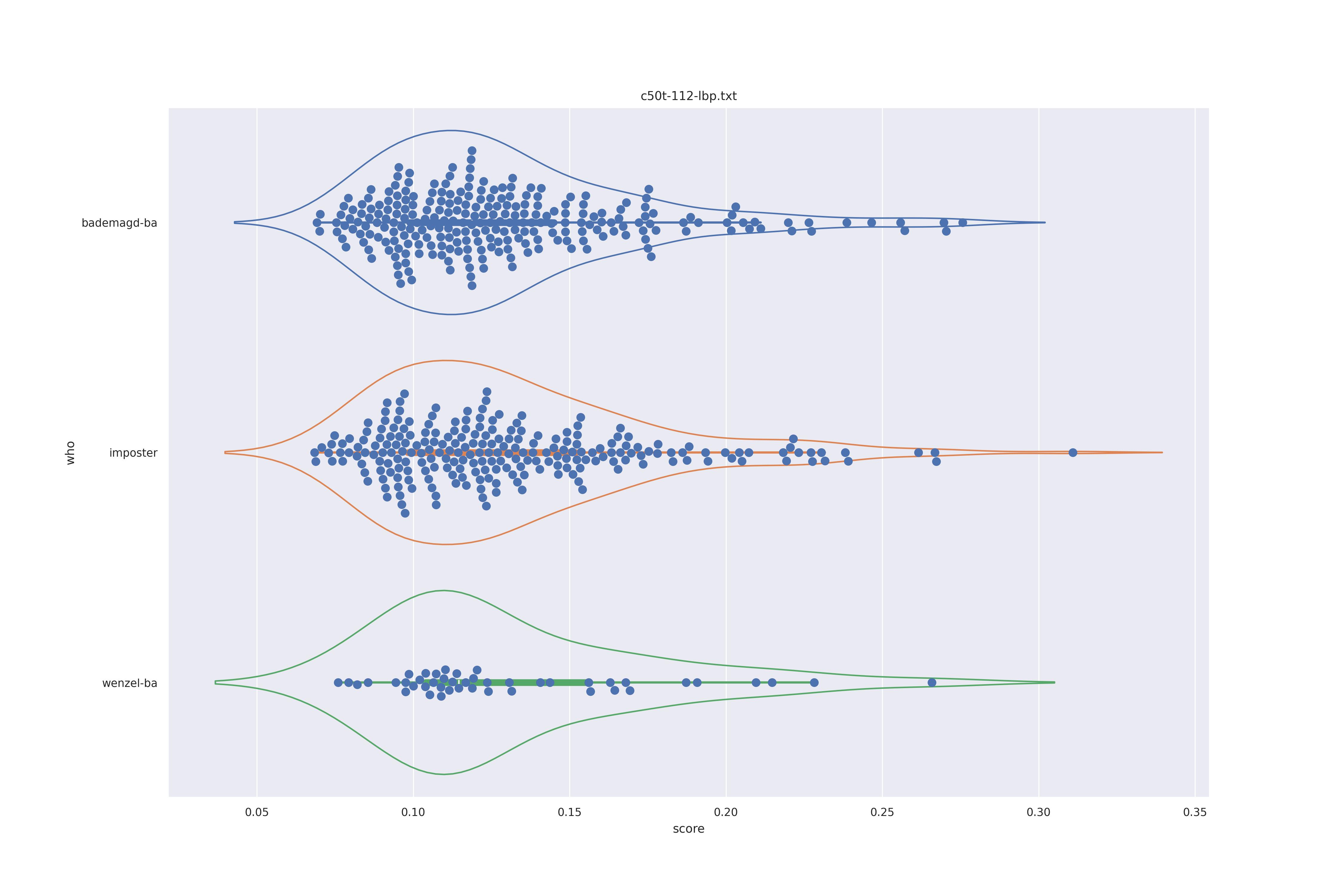 |
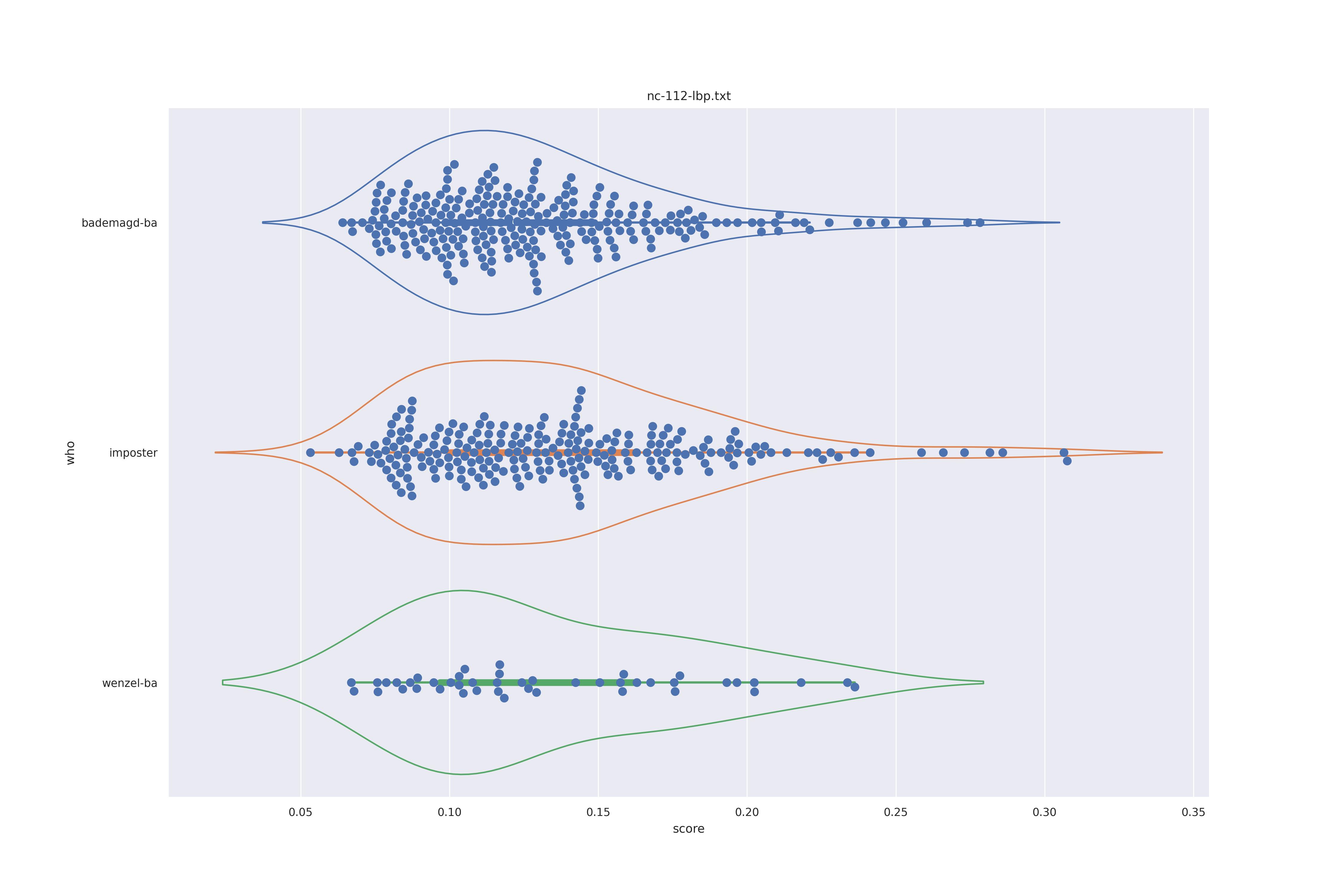 |
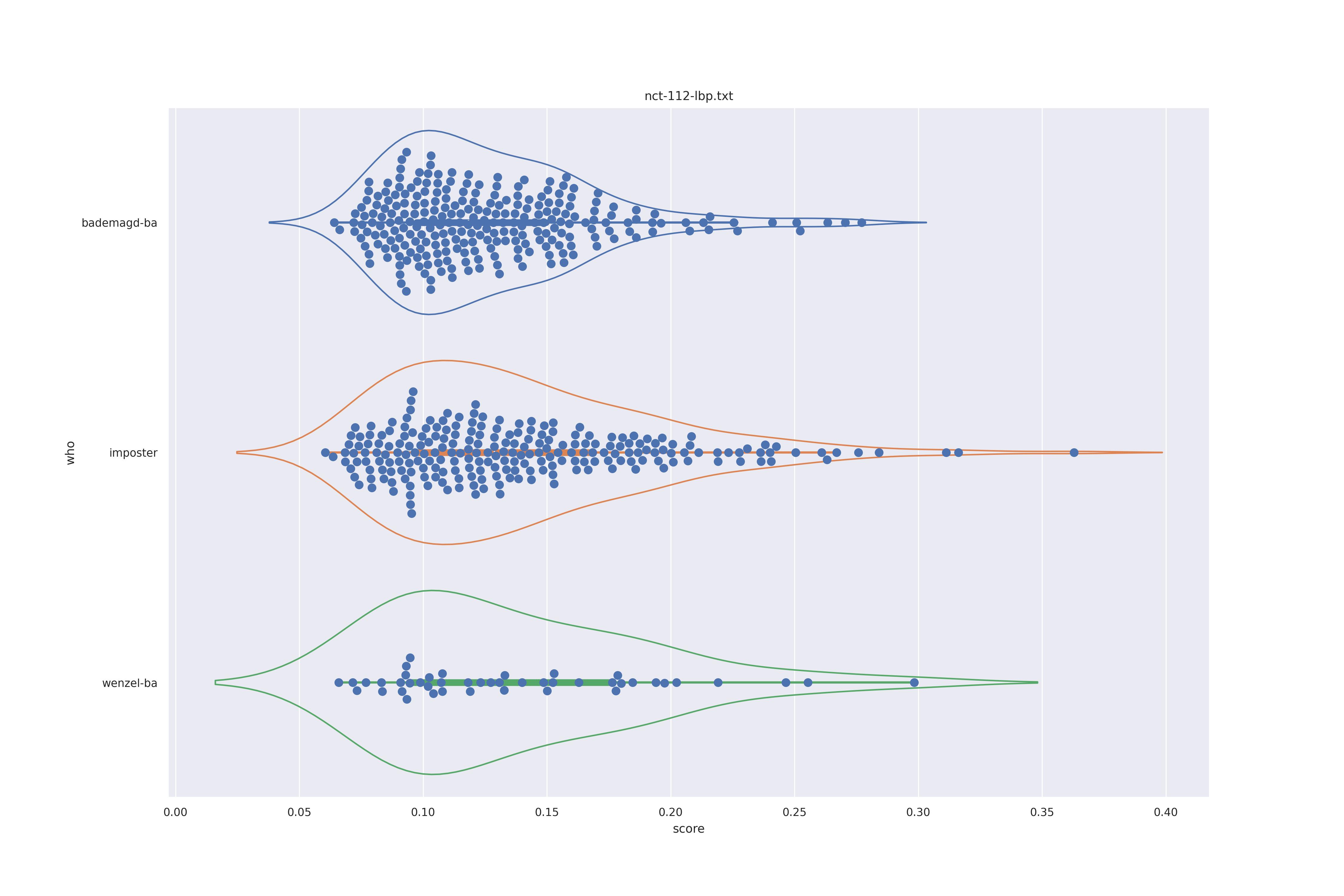 |
| lpips | 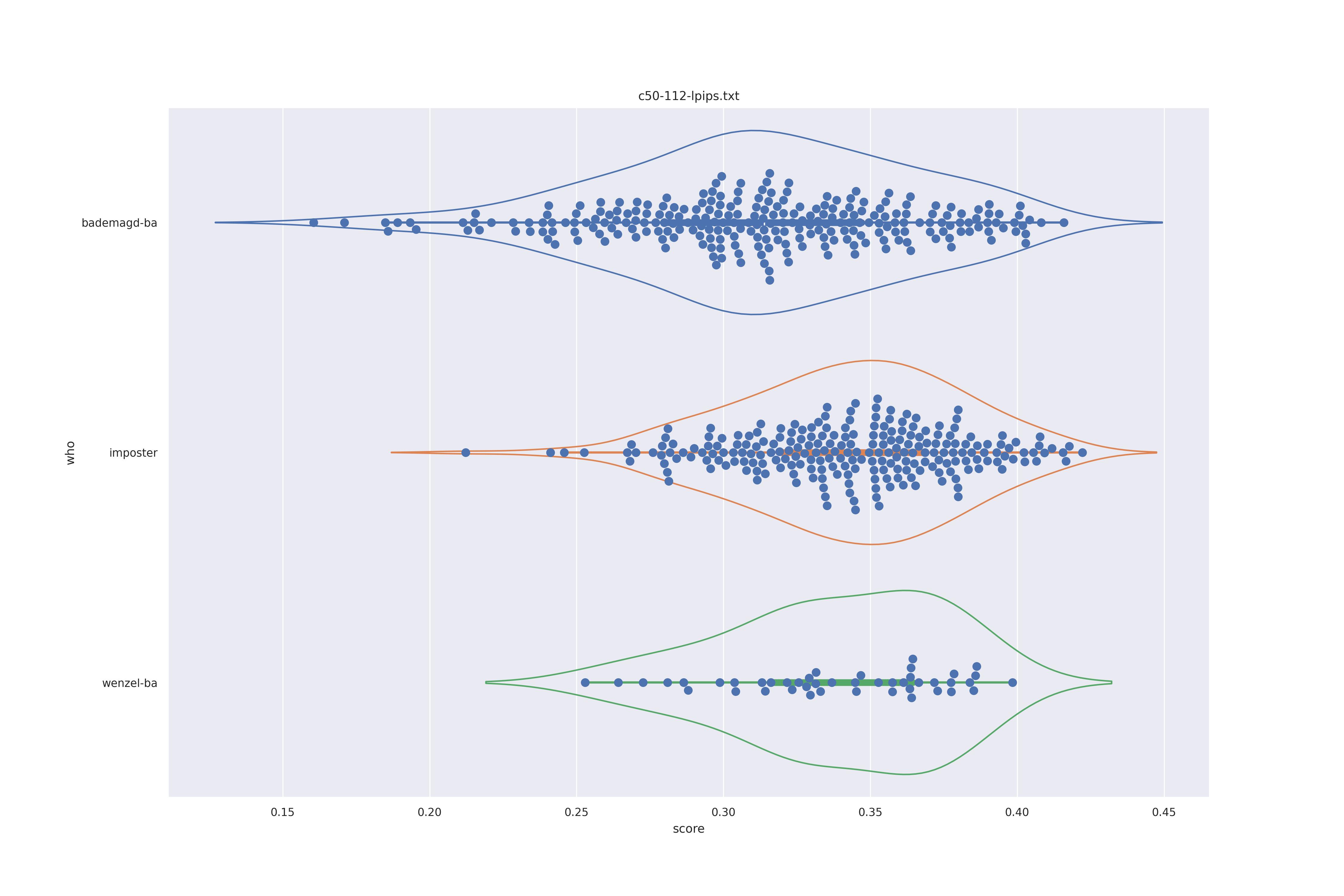 |
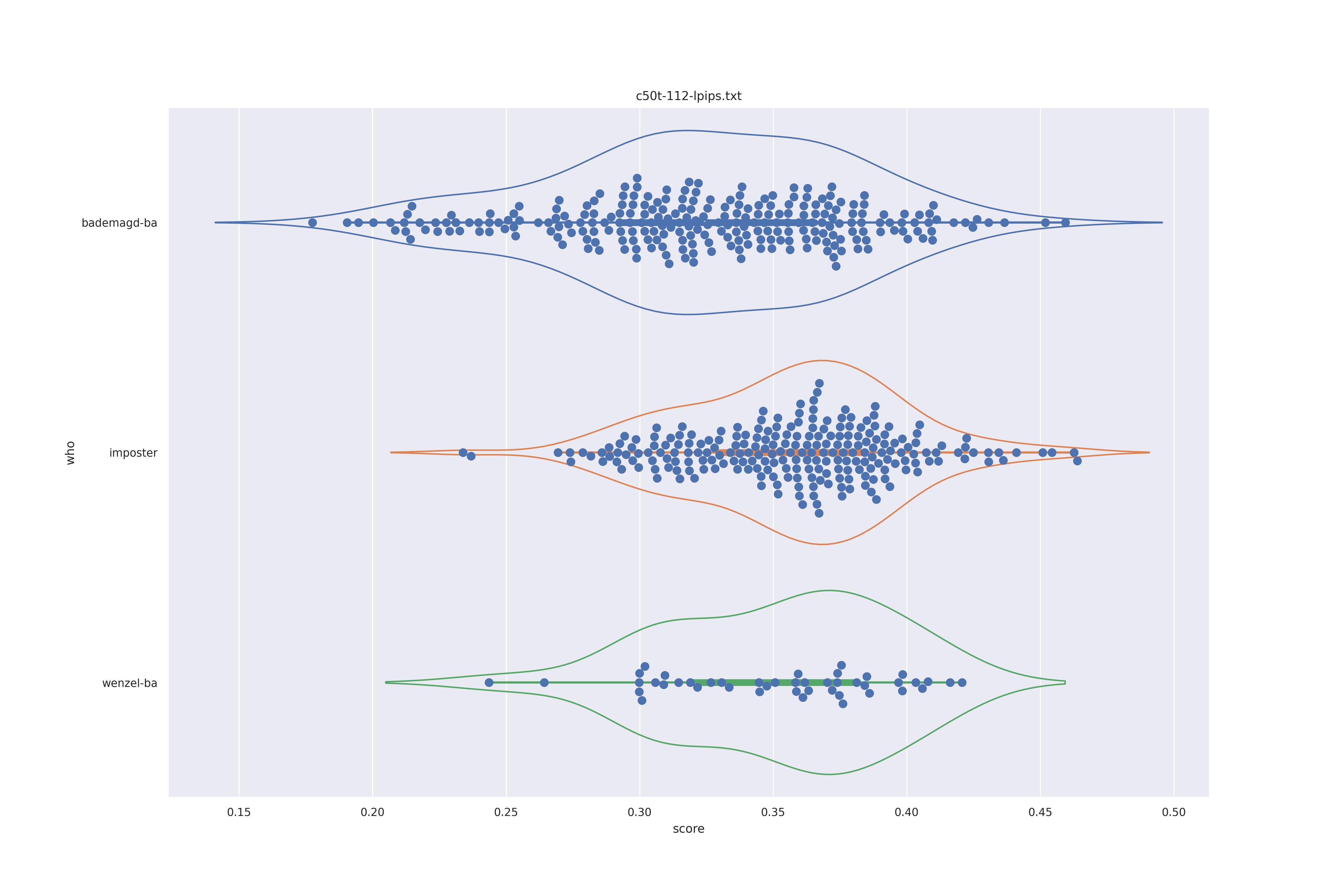 |
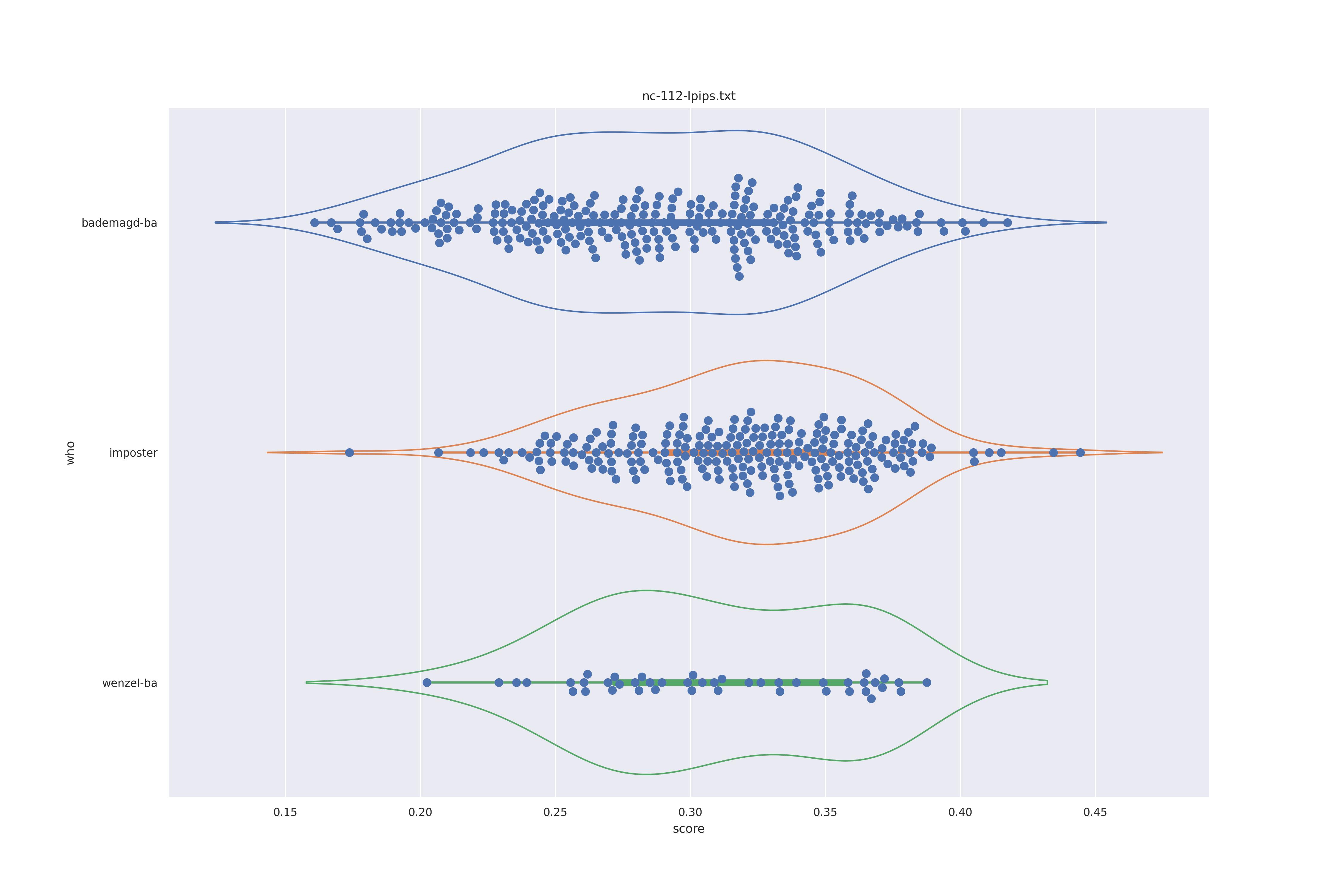 |
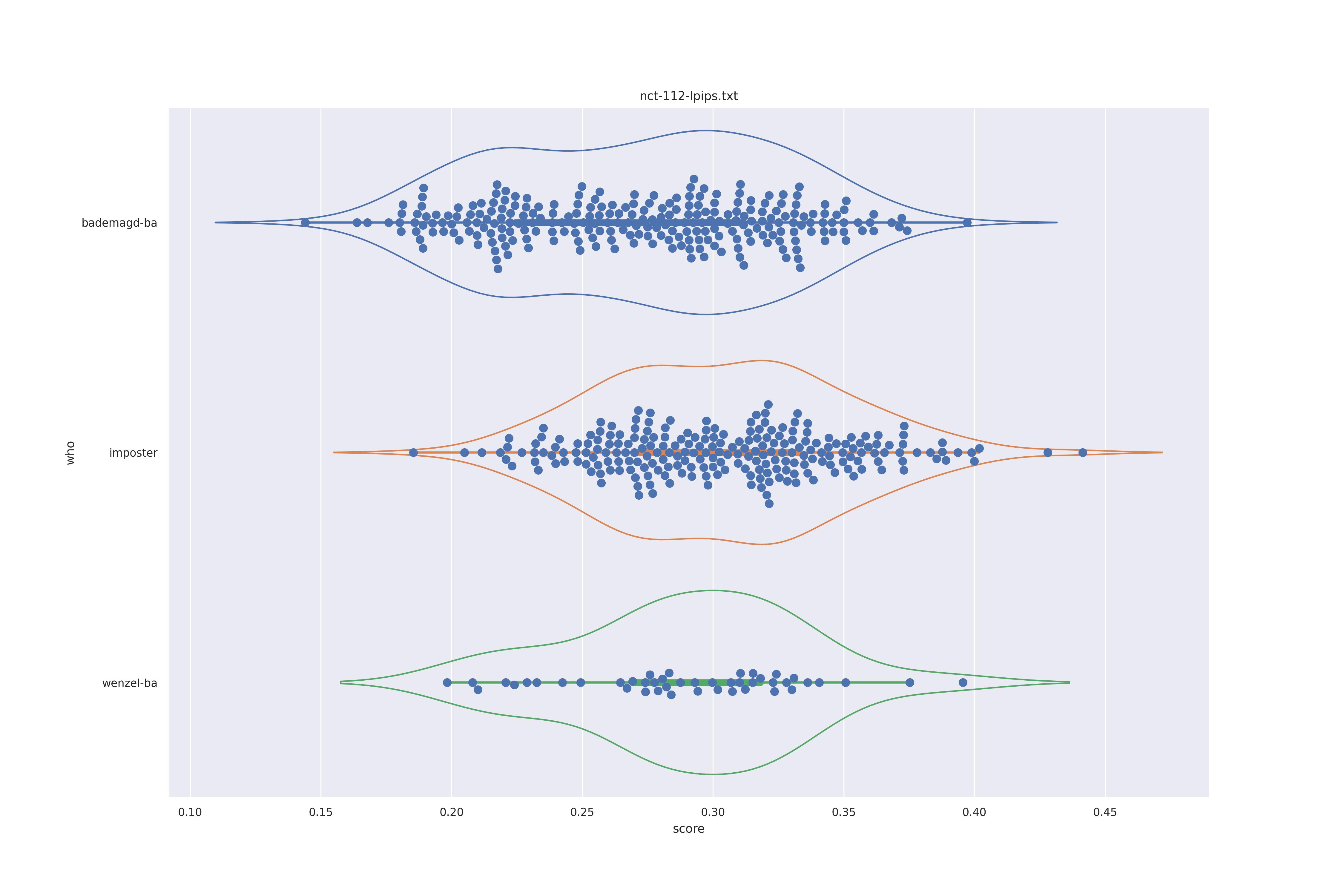 |
| hu | 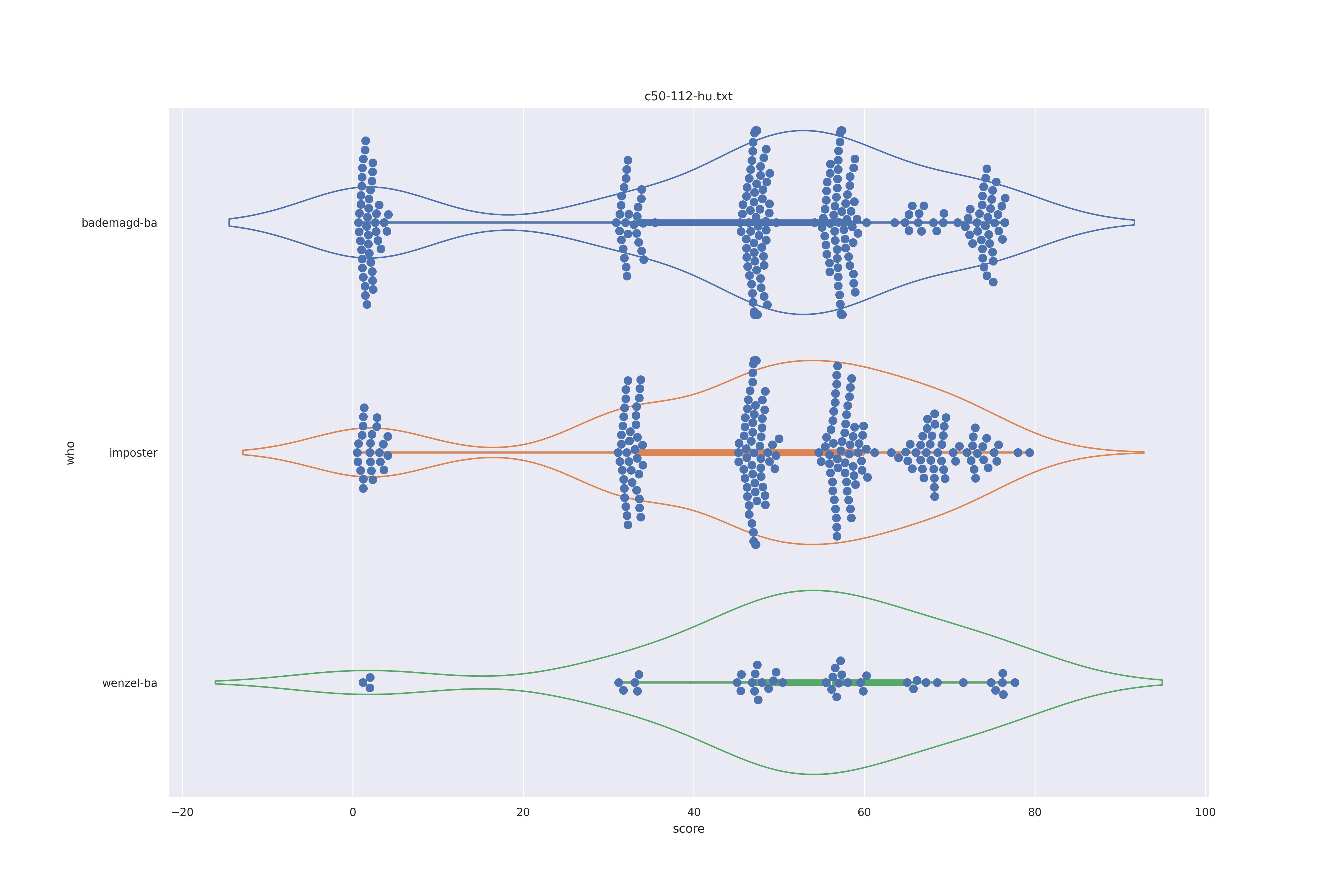 |
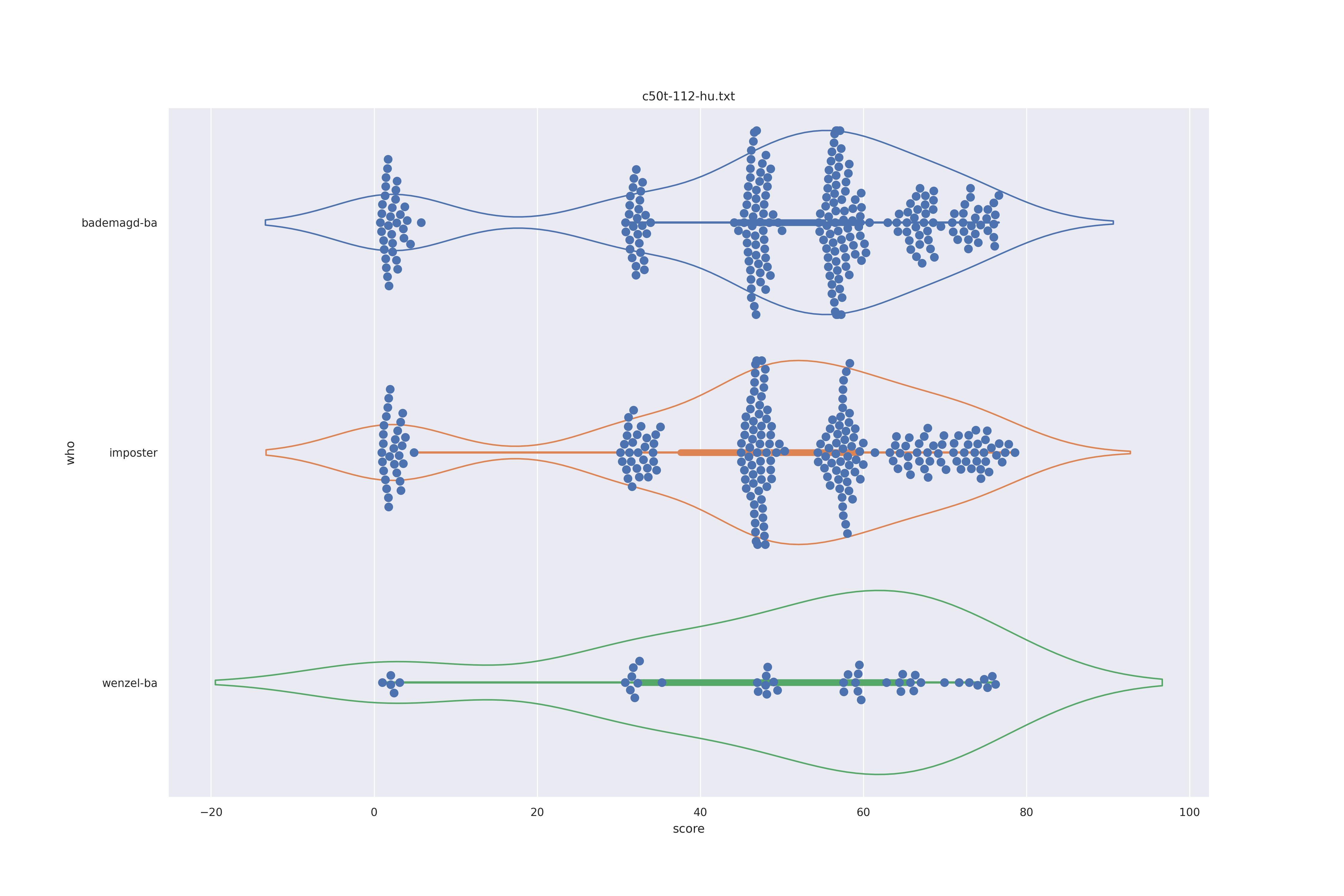 |
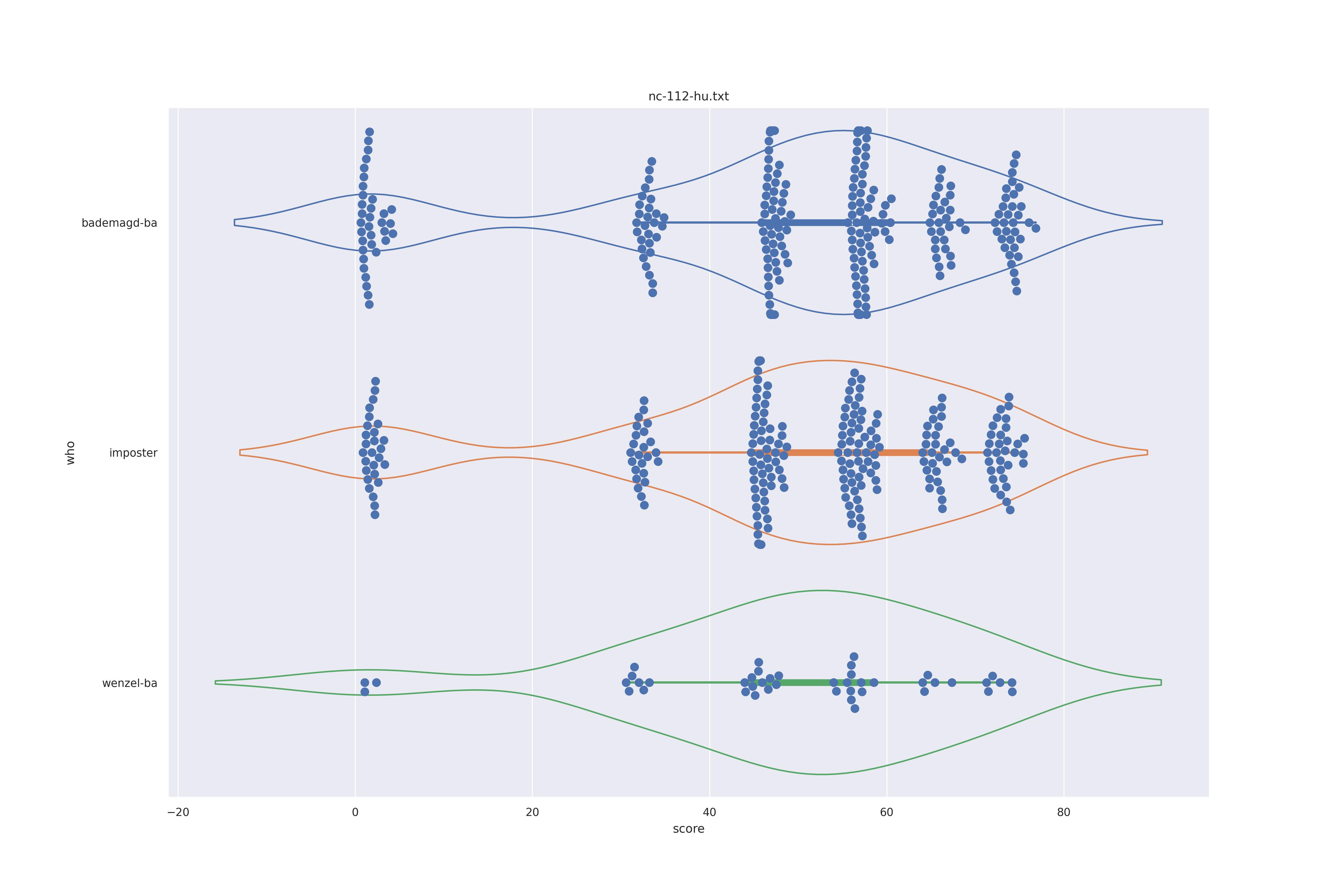 |
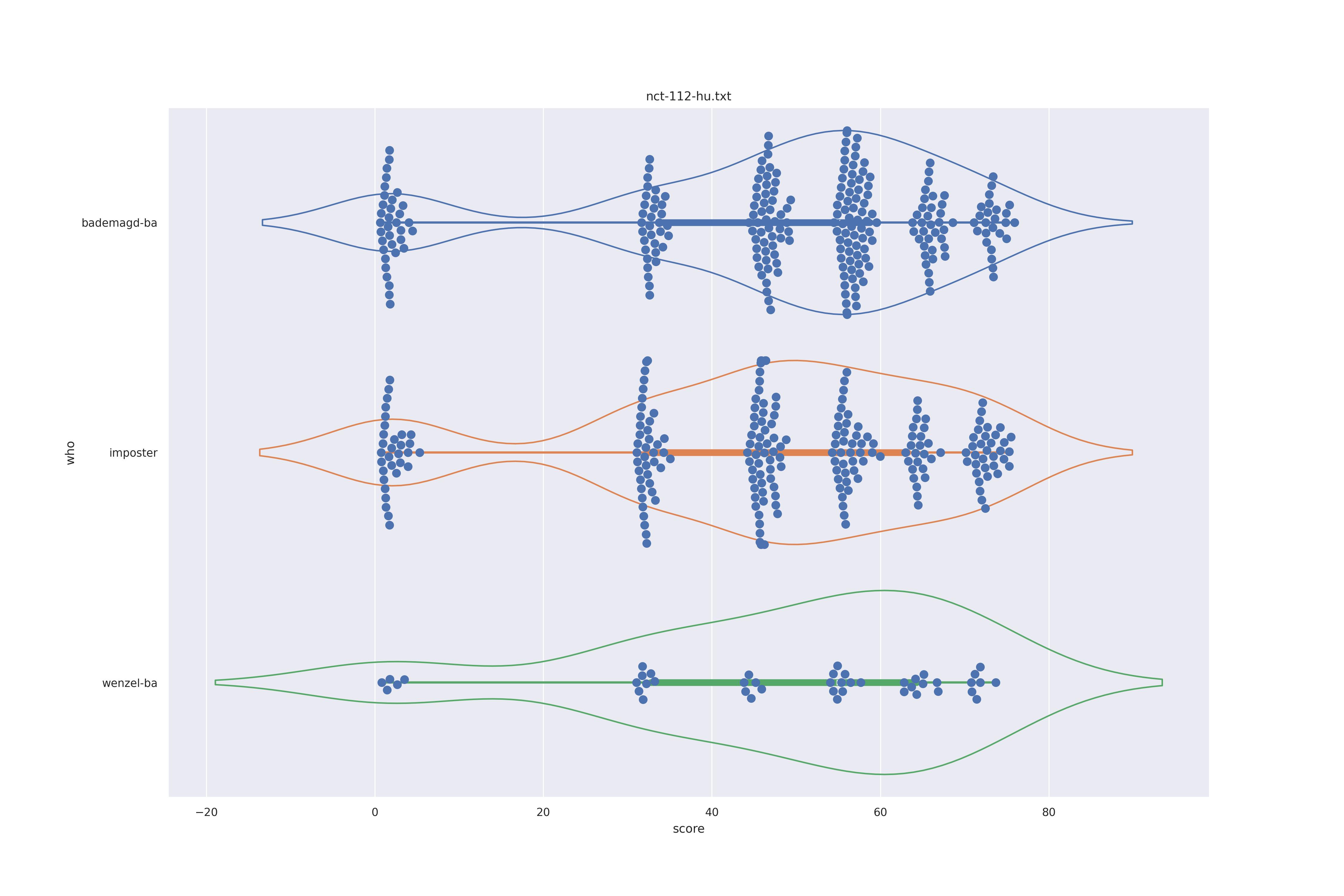 |
Overall all comparisons are very similar in that the genoine and imposter distributions are basically the same. In other words these methods are poor at differentiating the figures in the Wenceslas bibel. The usage of transforms or context slightly changes the distributions but the aforementioned statment still holds true.